We use MathJax
We have considered many different population distributions. We could take a sample from each of these distributions, and consider the distribution of sample means. The main implication of the Central Limit Theorem is that for any population distribution, for a sufficiently large sample, the distribution of sample means will be approximately normal. This result suggests that there is an interplay between the population and its samples, which we will begin investigating through an example.
Suppose that a biologist discovers two individuals of a new species of snake. He measures their lengths (among other characteristics) in order to provide information about this new species.
But before we focus on the biologist's findings, let us take a more omniscient view. Let us suppose that we know all about the population, even though the biologist does not. Unknown to him, the world population of this species of snake consists of exactly five individuals, whose lengths (in feet) are given by the values ${2,4,6,8,10}$. Some basic computations will reveal the following population parameters: $N = 5$, $\mu = 6$, $\sigma^2 = 8$, and $\sigma = \sqrt{8} \approx 2.83$. Furthermore, a graph will quickly confirm that the population is most similar to a uniform distribution.
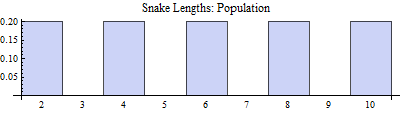
Simple probability questions can be asked about this population. For example, the probability that a randomly selected snake is between 4.5 and 7.5 feet long, by counting the relevant entries in the distribution, is $P(4.5 < x < 7.5) = \dfrac15 = 0.2$.
Now we know that the biologist found exactly two individuals. So let us consider all possible samples of size $n = 2$. From a counting argument, we know that there are precisely ${}_5 C_2 = 10$ possible samples, so it is a fairly easy task to write them all down. As we do so, we will also give the sample mean, $\bar{x}$, for each sample, since that is the measurement that the biologist would be reporting.
| Sample | 2, 4 | 2, 6 | 2, 8 | 2, 10 | 4, 6 | 4, 8 | 4, 10 | 6, 8 | 6, 10 | 8, 10 |
| Sample Mean | 3 | 4 | 5 | 6 | 5 | 6 | 7 | 7 | 8 | 9 |
Although there were 10 possible samples, we note that there were only 7 possible values for the sample mean. Some of the values could occur in more than one way. So if the two snakes that the biologist found were from a random sample, so that each sample would be equally likely to be found as any other, then some possible values of the sample mean are more likely than others. In other words, even though the population distribution was uniform, the distribution of sample means is not uniform. Let us display the probability distribution of the random variable $\bar{X}$, which is also called the sampling distribution of the mean.
| $\bar{x}$ | $P(\bar{X} = \bar{x})$ |
| 3 | 0.1 |
| 4 | 0.1 |
| 5 | 0.2 |
| 6 | 0.2 |
| 7 | 0.2 |
| 8 | 0.1 |
| 9 | 0.1 |
Because we have considered every possible sample, this distribution is a population of sample means. And we can determine the parameters of this population also. With some basic computations, we find: : $N_{\bar{x}} = 10$, $\mu_{\bar{x}} = 6$, $\sigma^2_{\bar{x}} = 3$, and $\sigma_{\bar{x}} = \sqrt{3} \approx 1.73$. The distribution is still symmetric, but it is not uniform.
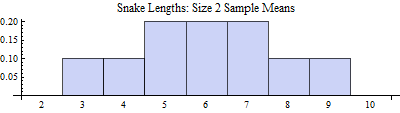
We can also ask simple probability questions about this distribution. The probability that a pair of randomly selected snakes has a mean length of between 4.5 and 7.5 feet long, by adding appropriate values from the PDF of the sample means, is
| $P(4.5 < \bar{x} < 7.5) = P(x=5) + P(x=6) + P(x=7) = 0.2 + 0.2 + 0.2 = 0.6$ |
Interestingly, and quite significantly, we see that it is much more likely for the sample mean to be between 4.5 and 7.5 feet than it is for a single individual to have that length.
Now the biologist only found one of those samples. Let us suppose he found the two largest individuals, having lengths 8 feet and 10 feet. In that case, he would report the following sample statistics: $n=2$, $\bar{x} = 9$, $s^2 = 2$, and $s = \sqrt{2} \approx 1.41$. Obviously, by reporting these values, the biologist is not accurately representing the population of snakes. This is not his fault, but is due to sampling error, which occurs whenever the characteristics of the sample do not match the population characteristics. Of course, that means sampling error almost always occurs. Yet the probability of having a very poor sample tends to be quite small, as long as the samples are random and sufficiently large.
Looking back at the example, we see that there were measurements at three different levels, the population, the sample, and the population of sample means. Notationally, we defined these quantities as:
The following three results describe the connection between the population and the distribution of sample means.
Suppose the random variable $X$ has a continuous uniform distribution on the interval $[0,20]$. What is the probability that a random sample of 30 values will have a sample mean between 8 and 12?
Suppose the mean household income in the USA is $\$51,344$, with a standard deviation of $\$15,377$. What is the probability that a random sample of 124 households will have a mean household income of more than $\$54,000$?